Нейрокомпьютерные интерфейсы позволяют считывать и обрабатывать данные об активности головного мозга, они, среди прочего, применяются для помощи пациентам с потерей речи, но пока им доступны в основном приборы, позволяющие управлять курсором с помощью движений головы или глаз, которые работают достаточно медленно по сравнению с обычной речью. В начале года в Scientific Reports вышла статья, авторам которой удалось обучить алгоритм воссоздавать речь из мозговой активности человека при ее прослушивании. Для этого они использовали активность аудиторной коры, полученной с помощью электродов, вживленных в мозг пациентов с эпилепсией, при прослушивании отдельных цифр, а затем синтезировали на ее основе короткие фразы. Получившаяся речь оказалась разборчивой в 75 процентах случаев.
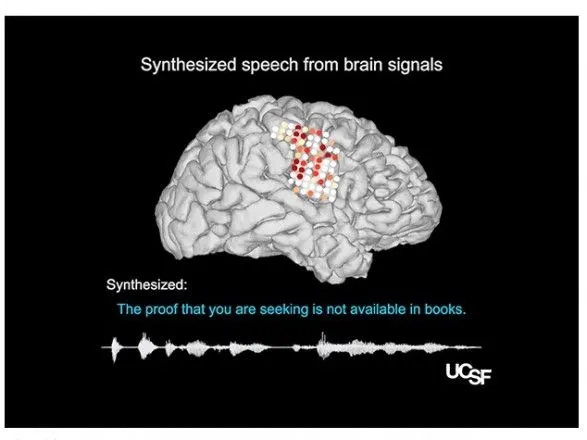
Группа под руководством Эдварда Ченга из Калифорнийского университета в Сан-Франциско предложила свой метод синтеза речи по мозговой активности при движении челюсти, гортани, губ и языка. По их словам, этот двухэтапный метод (распознавания активности мозга, связанной с движением органов речи, и трансформации этих сигналов в слова) сейчас позволяет точнее синтезировать речь, чем если бы добровольцы, к примеру, думали о заданных словах или даже просто предметах, хотя такие методы тоже интересуют ученых.
Они обучили одну рекуррентную нейронную сеть распознавать в активности вентральной сенсомоторной коры, верхней височной извилины и нижней лобной извилины элементы движения речевого тракта, а вторую сеть — распознавать в них акустические параметры речи, исходя из которых она затем синтезировалась.
Напоминаем, искусственный интеллект научился распознавать посттравматический синдром по голосу.